| Het testen van receptieve woordenschatkennis. (Marlon Hommersom) |
| home | lijst scripties | inhoud | vorige | volgende |
Het kennen van woordenschat is een zeer belangrijke vaardigheid bij het leren van een taal. Woorden brengen een betekenis over en de kennis van woorden laat ons die begrijpen. Over het algemeen betekent het leren van een taal dus woorden leren. Veel woorden leren. Andere aspecten van taal, zoals grammatica en uitspraak vereisen een grondigere analyse bij het leren van een taal. Woorden zijn echter directer. Zij zijn direct verbonden met een betekenis van een taal, waardoor docenten en studenten niet lang nodig hebben om het nut van het leren van woorden in te laten zien (Mobärg 1997). Maar wat is nu een
woord en wanneer ‘ken’ je een woord? Theoretici en onderzoekers discussiëren al lang over wat het inhoudt om een woord te kennen. Zie voor een overzicht Wesche en Paribakht (1996). Er zijn verschillende theorieën over, maar een eenduidige definitie is nog niet gevonden. Drie benaderingen om de betekenis van een woord uit te leggen staan beschreven in Bogaards (2000). Hij beschrijft de verschillende lijsten met kenmerken van een woord die zijn opgesteld door Cronbach (1942), Richards (1976) en Nation (1990). Zo zegt Cronbach dat het kennen van een woord uit 5 aspecten bestaat: generalisatie (een definitie weten), toepassing (kennis van de toepassing van een woord), diepte van de betekenis (meerdere betekenissen van een woord kennen), precieze betekenis (weten hoe een woord gebruikt moet worden in verschillende situaties) en toegankelijkheid (weten hoe een woord productief gebruikt moet worden). Richards geeft 7 criteria voor het kennen van een woord:
Weten hoe waarschijnlijk het is om het woord in spreektaal of schrijftaal tegen te komen.
Beperkingen door variatie, functie en situatie in het gebruik van het woord kennen
De syntactische regels van het woord kennen.
De onderliggende vorm van een woord kennen en de afleidingen die van het woord gemaakt kunnen worden.
Kennis van het associatief netwerk tussen het woord en andere woorden in de taal.
De semantische waarde van het woord kennen.
De verschillende betekenissen van het woord kennen.
Nation tenslotte heeft een onderscheid gemaakt tussen vier dimensies van woordkennis: vorm (mondeling of schriftelijk), positie (grammaticaal), functie (frequentie en geschiktheid) en betekenis (conceptueel en associatief). Boogaards (2000) bespreekt vervolgens hoe deze drie benaderingen elkaar aanvullen. Hij laat zien dat Nation aspecten toevoegt die te maken hebben met de geschreven of gesproken vorm van het woord, maar dat hij het niet heeft over de problemen bij de morfologie, wat wel wordt gedaan door Richards. En terwijl Cronbach niets meldt over associaties, zegt Nation niets over de polysemie van woorden. In deze drie benaderingen wordt een woord gezien als een eenheid waarvan men kennis heeft. Het “kennen” van een woord wordt echter niet gespecificeerd. Naar mijn idee vullen deze drie benaderingen elkaar aan. Alle drie de benaderingen apart missen een onderdeel, maar door ze samen te nemen wordt een completeren benadering gevormd.
Deze scriptie gaat over het testen van receptieve woordenschatkennis. Hierbij ga ik dieper in op de ja/nee-test van Paul Meara en de pvt-test door middel van een onderzoek. Het doel van mijn onderzoek is een ja/nee-test ontwikkelen voor het Frans en deze testen bij Nederlandstalige studenten. Dit is nog niet gedaan voor het Nederlands. Ook heb ik als doel deze ja/nee-test te valideren. In het eerste hoofdstuk van deze scriptie probeer ik globaal een antwoord te geven op de vraag ‘wat is een woord’, door verschillende indelingen van woordenschatkennis te geven. Daarbij geef ik enkele voorbeelden van woordenschattesten. In hoofdstuk 2 ga ik in op het ontwikkelen van een woordenschattest. Hoe wordt dat over het algemeen gedaan en welke opvattingen spelen daarin een rol? In hoofdstuk 3 bespreek ik een aantal tests voor receptieve woordenschat. Hier introduceer ik de ja/nee-test en de paired vocabulary test, die ik zal gebruiken in mijn onderzoek. Dit onderzoek beschrijf ik in hoofdstuk 4. Het betreft een onderzoek, waarin ik de ja/nee-test van Paul Meara heb aangepast en er een test voor Nederlandse leerders van het Frans van heb gemaakt. Ik bekijk hoe deze test werkt ten opzichte van een andere test van receptieve woordenschatkennis, de paired vocabulary test, en ik gebruik een vertaaltaak als validering van beide tests. Ook voeg ik een nieuw component toe aan de test, het taalportfolio, om te kijken of studenten zelf een beeld kunnen geven van hun eigen algemene vaardigheden in het Frans. In hoofdstuk 5 geef ik de resultaten van het onderzoek voor alle vier de onderdelen van mijn test, waarna ik in hoofdstuk 5 de bespreking van de resultaten en de conclusie behandel.
1.2 Indelingen van woordenschatkennis
De meest algemene – en meest gebruikte indeling van woordenschatkennis zijn brede- tegenover diepe woordkennis en receptieve- tegenover productieve woordenschatkennis. Ook kan er een onderscheid gemaakt worden tussen algemene- en specifieke woordenkennis. Hieronder zal ik een beeld geven van deze drie indelingen van woordenschatkennis.
1.2.1 Breedte van woordkennis versus diepte van woordkennis
Met het begrip breedtekennis wordt verwezen naar het kwantitatieve aspect van woordenschatkennis. Het gaat daarbij om de kennis van het aantal woorden en de beheersing van de ermee verbonden conceptuele kennis. Het begrip dieptekennis is daarentegen gebaseerd op het principe dat een woord veel meer is dan zijn denotatieve betekenis. Een woord wordt in deze opvatting gezien als een deel van het mentale lexicon, waar een heel semantisch netwerk omheen wordt gebouwd. Het testen van breedte van woordkennis wordt vaak gedaan door multiple choice tests, matching pairs, tweetalige woordenlijsten, woorden in context en cloze tests. Diepe woordkennis wordt vaak getest door vrije woordassociaties, woordparen en definities. Enkele voorbeelden van woordenschattests die gericht zijn op het toetsen van diepe woordkennis staan beschreven in de volgende artikelen:
1) De ontwikkeling van een dieptetoets woordenschatkennis op basis van substantief + werkwoord (Neven 2002). De toets werd afgenomen bij Franstalige proefpersonen die het Nederlands al vrij goed beheersen. Met de toets probeert men een zo gedetailleerd mogelijk beeld krijgen van de diepe kennis van woorden die al tot de actieve breedtekennis behoren. In de toets moeten de proefpersonen bij een substantief een keuze maken uit onderstaande vier antwoorden. Eén, twee of drie antwoorden vertegenwoordigen woorden die een relatie hebben met het bovenstaande woord en minstens één woord dat geen relatie heeft met het woord. Hierdoor worden de proefpersonen voorzichtiger met het invullen van de tests en wordt het mogelijk gemaakt om mensen die veel gokken op te sporen. De toets ziet er als volgt uit:
|
Beroep |
|||
|
ambacht |
schreeuw |
vak |
verzoek |
|
0 |
0 |
0 |
0 |
|
Genoegen |
|||
|
plezier |
gegadigde |
gemak |
genot |
|
0 |
0 |
0 |
0 |
2) De ‘Words Associates Test’ (Read 1993) probeert diepe woordkennis te testen. In deze test worden de items gevormd door een doelwoord en 8 andere woorden. Vier daarvan hebben een soort relatie met het doelwoord, terwijl de andere vier dat niet hebben. De proefpersonen moeten de vier woorden selecteren die een relatie hebben met het doelwoord. Na een pre-test, gaf Read twee testen die elk bestonden uit 50 items. Deze twee testen werden gemaakt door meer dan 200 leerders van het Engels. Een voorbeeld van deze test is:
|
plotseling
|
|
|
|
|
|
|
|
|
prachtig |
snel |
verrassend |
dorstig |
verandering |
dokter |
lawaai |
onverwacht |
3) De ‘Euralex French Test’ (Meara 1992a). In een onderzoek van Boogaards (2000) wordt gekeken naar diepte woordkennis van het Frans op een hoog niveau. Daarvoor zijn de proefpersonen uitgekozen op een universiteit in Nederland, die in het 1e t/m het 4e jaar van hun studie Frans zitten. De proefpersonen krijgen een groot aantal items die bestaan uit twee woorden waarbij de volgende vraag beantwoord moet worden: zijn deze woorden op één of andere manier aan elkaar gerelateerd of niet? In totaal zijn er vier verschillende relaties te onderscheiden. Ten eerste kan deze relatie semantisch zijn waarbij een woord gekozen kan worden dat een synoniem, hyponiem of antoniem is, bijvoorbeeld rustig – druk. Ten tweede kan er een relatie zijn tussen collocaties en een bepaald werkwoord die altijd samen voorkomen, zoals paard - rijden. Ook kan de relatie een vaste uitdrukking zijn, zoals met de mond vol tanden staan. Tenslotte kan de relatie een cultureel aspect weergeven, bijvoorbeeld Sinterklaas vieren. Het format ziet er als volgt uit:
1. isoloir: élection [ ] 2. bateau: mouche [ ]
3. affût: chasseur [ ] 4. agréable: dents [ ]
In het onderzoek zijn in totaal 60 items, waarvan 40 items aan elkaar gerelateerd zijn en 20 items geen enkele relatie hebben. In totaal werden vier soortgelijke tests uitgevoerd waaronder een pretest onder docenten, twee testen onder alle studenten Frans van het 1e t/m het 4e jaar en de vierde test onder de studenten die op de tweede test een score tussen de 50 en 90 procent hadden. Uiteindelijk bleek dat, ook al waren de correlaties onderling niet hoog, dat de vierde test een betere voorspeller was van taalvaardigheid dan de twee testen onder alle studenten Frans. Dit komt waarschijnlijk doordat er voor taalvaardigheid een bepaald niveau aan woordkennis behaald moet zijn om de test goed te maken. De eerstejaars studenten zullen dit niveau nog niet bereikt hebben.
Bij de volgende indelingen komen er enkele niet-diepe woordenschattoetsen aan bod. Ook in mijn onderzoek zal ik gebruik maken van niet-diepe toetsen, omdat de ja/nee-test waarop mijn test is gebaseerd, juist erg handig is om te de breedte van woordkennis te testen. In hoofdstuk 3 zal ik deze test en zijn voordelen uitgebreid behandelen.
1.2.2 Receptieve woordkennis versus productieve woordkennis
Een tweede indeling van woordkennis is die tussen het receptief kennen van een woord en het productief kennen van een woord. Met het receptief kennen van een woord wordt bedoeld dat men een woord wel herkent en weet wat het betekent, maar het woord niet noodzakelijkerwijs zelf kan gebruiken. Productieve kennis van een woord wil dus zeggen dat men het woord kent en ook kan gebruiken. Een voorbeeld van een receptieve test kan gevonden worden in een artikel van Nation (1983, 1990) “Vocabulary Levels Test”. In deze test moeten leerders drie van de zes woorden matchen met een passende parafrase van dat woord. Deze woorden worden in isolatie getest; er wordt geen contextuele informatie bij de woorden gegeven. De test ziet er als volgt uit:
You must choose the right word to go with each meaning. Write the number of that word next to its meaning.
|
1. concrete |
|
|
2. era |
|
|
3. fiber |
--------- circular shape |
|
4. hip |
--------- top of a mountain |
|
5. loop |
--------- a long period of time |
|
6. summit |
|
Het doel van deze test is het zien van de hoeveelheid woorden die de proefpersonen begrijpen zonder contextuele informatie. In totaal bestaat de test uit 5 secties, die elk bestaan uit 18 items.
Een ander voorbeeld van een receptieve test is de ‘yes/no-test’ van Paul Meara (1987). In deze tests moeten proefpersonen aangeven of ze een woord wel of niet kennen. In de test zitten pseudowoorden verwerkt als controlemiddel. Een proefpersoon die hoog scoort heeft volgens het format de pseudowoorden verworpen. De test ziet er als volgt uit:
Zet een kruis achter de woorden waarvan je de betekenis kent.
|
Gathering |
Crope |
Untamed |
|
Forgivity |
Tropical |
Judgement |
|
Whistle |
Success |
Heartless |
|
Draven |
Repeat |
Bluck |
Later werd de test aangepast en veranderde de layout. De test zag er toen als volgt uit:
Geef aan of u het woord wel of niet kent. Omcirkel uw antwoord.
|
Gathering |
yes |
no |
|
Forgivity |
yes |
no |
|
Whistle |
yes |
no |
|
Draven |
yes |
no |
|
Crope |
yes |
no |
|
Tropical |
yes |
no |
In hoofdstuk 3 zal ik verder op ingaan op de ja/nee-test.
Een laatste voorbeeld van een test voor receptieve woordkennis is de pvt-test (Beeckmans e.a. 2002), waarin een bestaand woord naast een niet bestaan woord wordt gezet. In deze test moet er worden gekozen welk van de twee woorden een bestaand woord is. In hoofdstuk 4 zal ik hier verder op in gaan.
1.2.3 Algemene woordkennis versus specifieke woordkennis
Een laatste onderscheid kan er nog gemaakt worden tussen algemene woordkennis en specifieke woordkennis. Bij algemene woordkennis wordt er gekeken naar het aantal woorden dat je kent. Bij specifieke woordkennis wordt er gekeken naar hoeveel woorden je kent binnen een bepaald domein. Dit wordt veelal gedaan bij het testen van de woordkennis bij een bepaalde doelgroep, bijvoorbeeld bij mensen die een managerscursus Frans volgen. In een woordenschattest voor deze mensen zullen woorden staan die binnen het domein van het management vallen. Er bestaat een duidelijk verband tussen de drie indelingen van woordkennis. Algemene woordkennis en specifieke woordkennis kunnen getest worden via receptieve en productieve woordkennis en door te kijken naar de breedte van de woordkennis en de diepte van de woordkennis.
2. Het ontwikkelen van een woordenschattest
Met al die verschillende types woordkennis, zoals beschreven in hoofdstuk 1, is het niet eenvoudig om een woordenschattest te ontwikkelen die hierop aansluit. Daarom zijn er veel verschillende tests ontwikkeld, afhankelijk van het type kennis dat men wil testen. In de laatste jaren zijn er verschillende studies geweest die zich richtten op het meten van woordenschatkennis. Zo zijn er diverse tests ontwikkeld zoals de Vocabulary Levels test (Nation 1983), de C-test (Singleton en Little 1991, Chapelle 1994), de Lexical Frequency Profile (Laufer en Nation 1995) en de Vocabulary-size Test of Controlled Productive Ability (Laufer en Nation 1999).
Bij het beslissen voor een bepaalde vorm waarin de woordenschattest gegoten moet worden moeten er eerst verschillende beslissingen genomen worden. Read (1993) zegt in de inleiding van zijn Word Associates Test dat men bij de keuze voor een bepaalde testformat voor een woordenschattest rekening moet houden met de volgende aspecten:
Een eenvoudig of meer complex testformat (waarbij de ja/nee-test een simpele vorm is)
Controleerbare antwoorden of meningen van proefpersonen (als de proefpersonen bijvoorbeeld moeten aangeven of ze een woord wel of niet kennen)
De grootte of de kwaliteit van kennis (gaat het erom hoeveel woorden de proefpersonen kent (brede woordkennis) of om de diepte van de woordkennis (diepe woordkennis)
Testen van de woorden in context of in isolatie
Hierbij zou dus nog een punt moeten met: testen van passieve woordkennis of receptieve woordkennis. Joe, Nation en Newton (1988) beschrijven acht verschillende testformatten die, door het combineren van drie factoren die de moeilijkheid van een testitem beïnvloeden, zijn ontwikkeld. In hun artikel is het verschil tussen receptieve woordkennis en productieve woordkennis wel toegevoegd. Zij noemen als karakteristieken van een woordenschattest:
Een onderscheid tussen receptief en productief (passief/ actief) kennen van een woord.
Een onderscheid tussen herkenning en zelf oproepen van een woord (bv. een verschil tussen multiple choice en een zelf in te vullen toets).
Een onderscheid tussen het niet precies en precies kennen van een woord. Dus herken je een woord wel, maar weet je de betekenis niet. Of weet je zelfs verschillende betekenissen van het woord.
Een belangrijke vraag bij het ontwikkelen van een test voor woordenschatomvang is: welke woorden gebruik ik in de test? Het maken van een selectie van woorden kan op vele manieren. De meest voor de hand liggende manier is om te kijken welke woorden voorkomen in studieteksten, om daar vervolgens de meest voorkomende woorden uit te selecteren. Op deze manier wordt een frequentielijst samengesteld, met daarop woorden in volgorde van het aantal keer voorkomen in een tekst. De betrouwbaarheid van een dergelijke woordenlijst is echter direct afhankelijk van de corpusgrootte en de corpussamenstelling. De mate waarin een frequentielijst representatief is voor bijvoorbeeld algemeen taalgebruik is afhankelijk van de diversiteit aan teksten die zijn opgenomen in het corpus. Daarom wordt er voor het maken van een frequentielijst gebruik gemaakt van verschillende bronnen om op deze manier te kunnen kijken naar het aantal malen dat een bepaald woord voorkomt in verschillende teksten. Woorden die in veel verschillende contexten gebruikt worden, zijn vanzelfsprekend frequenter dan woorden die aan specifieke situaties gebonden zijn. Er is een groot verschil in frequentielijsten. De eerste 200 woorden zullen ongeveer hetzelfde zijn in elke lijst, maar de grootte van de lijst daarna is afhankelijk van het gekozen corpus. Niet bij alle frequentielijsten draait het puur om frequentie. Vaak wordt er rekening gehouden met een bepaalde doelgroep. Als er bij een bepaalde doelgroep wordt getest wordt er vaak gebruik gemaakt van een bepaald frequentiebereik. Voor beginnende leerders wordt bijvoorbeeld gekozen voor woorden met een hoge frequentie, dus uit het bereik 0-1000, terwijl voor gevorderde leerders gekozen kan worden voor de frequentie 4000-5000. In overleg wordt de lijst dan verder samengesteld. De woorden waar ik gebruik van maak in mijn onderzoek komen uit de frequentielijst van Juilland (1970). De lijst is al ruim 30 jaar oud, maar toch de meest actuele. In het boek staan 5083 woorden op frequentie geselecteerd. In mijn onderzoek heb ik gebruik gemaakt van de eerste 2000 woorden, waarvan ik er een aantal heb geselecteerd. In hoofdstuk 4 zal ik hier verder op in gaan.
Hoe belangrijk het kennen van een groot aantal van deze woorden is voor bijvoorbeeld het lezen van een tekst laat Hazenberg (1994) in haar proefschrift zien. Zij zegt: ‘het kunnen lezen van een tekst houdt in dat men al een bepaalde woordenschat moet hebben opgebouwd. De T2-lezer heeft woordkennis nodig om nieuwe woorden uit teksten te kunnen leren. De vraag is dan hoeveel en welke woorden men nodig heeft om met enig gemak een (studie)tekst te kunnen lezen’. Het eerste probleem is het definiëren van de term ‘woord’. Daar bestaan verschillende opvattingen over: de een telt afkortingen, eigennamen, affixen e.d. mee, de ander niet. Ook tellen sommige onderzoekers woordvormen ook mee. Hazenberg zegt dat een basiswoordenschat van 1000 à 2000 woorden ontoereikend blijkt te zijn om met enig gemak (studie)teksten te lezen. ‘Het is met name een gebrek aan kennis van subtechnische en laagfrequente woorden die T2-tekstbegrip in de weg staat’. In haar onderzoek toont zij aan dat voor een bevredigende mate van tekstdekking een receptieve kennis van ruim 11000 woorden (basiswoorden die een zelfstandige ingang vormen tot het woordenboek, dus geen affixen en verwijzingen e.d.) noodzakelijk is. Hiermee wordt bedoeld dat dit aantal woorden receptief gekend moet zijn om een bepaalde tekst goed te kunnen lezen en begrijpen. Niet alle woorden hoeven dan gekend te zijn, want deze kunnen afgeleid worden uit de context.
In deze scriptie zal ik me beperken tot receptieve woordkennis. In dit hoofdstuk zal ik daar verder op in gaan. Waarom zou men receptieve woordenschat testen? Receptieve woordenschatkennis is een essentieel onderdeel van woordenschatkennis. Wesche en Paribakht (1996) benadrukken dat het voor tweedetaal leerders zeer belangrijk is om verschillende tests te hebben waarbij de verschillende aspecten van woordenschatkennis (dus zowel brede - als diepe woordkennis, passieve- als receptieve woordkennis) worden gemeten. Dit geeft een inzicht in het verwerven van woorden in een tweede taal, wat nuttig kan zijn voor de beheersing van alle vaardigheden in een taal. De vraag die vaak centraal staat bij het testen van receptieve woordenschatkennis is “Wat is de totale grootte van de woordenschatkennis van de taalleerders?”
Eén van de bekendste testen die daarop een antwoord probeert te geven is de ja/nee-test van Meara en Buxton (1987). De test zelf is niet nieuw. Dergelijke testen werden al eerder afgenomen bij eerste taalleerders. Het nieuwe aan de ja/nee-test is dat deze wordt afgenomen bij tweede taalleerders. Typisch voor de ja/nee-test is de aanwezigheid van bestaande woorden en pseudowoorden. Deze pseudowoorden zijn woorden die voldoen aan de fonotactische regels van een taal, maar geen betekenis dragen. Enkele voorbeelden zijn:
|
* |
amoir |
|
* |
meuver |
|
* |
rirer |
|
* |
taiser |
Deze pseudowoorden zijn als controlemiddel in de test ingevoegd. De items van een ja/nee-test bestaan telkens uit één woord dat visueel wordt aangeboden. De proefpersoon moet per aangeboden woord aangeven of hij het woord wel of niet kent. De proefpersonen weten dat er in de test pseudowoorden zijn opgenomen, alleen niet hoeveel en waar in de test. Enkele voordelen van de ja/nee-test ten opzichte van de eerder gebruikte multiple choice-tests zijn:
- het ontwikkelen van de test neemt niet veel tijd in beslag
- het invullen van een ja/nee-test neemt niet veel tijd in beslag
- het testen van een groter aantal items is daardoor mogelijk
- de test kan hierdoor een beter beeld geven van de totale woordkennis, wat bij de multiple choice tests niet het geval was. Deze zijn vooral effectief bij het testen van woordkennis op een lager vaardigheidsniveau.
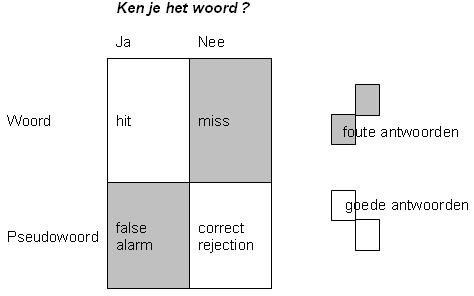
Bij het scoren van de Ja/nee-test moet er rekening mee worden gehouden dat er twee soorten goede antwoorden en twee soorten foute antwoorden zijn. Hierdoor ontstaan er vier mogelijke combinaties die hieronder staan weergegeven. Vooral het aantal false alarms is erg belangrijk bij het berekenen van een score op de test, aangezien die aangeven hoe vaak een proefpersoon zegt een woord te kennen dat niet bestaat.
Figuur 3.1 Schematisch overzicht antwoorden op de ja/nee-test
Doordat er dus twee goede antwoorden (hit en correct rejection) en twee foute antwoorden (miss en false alarm) zijn, is het berekenen van een score op deze test erg lastig. Daarom zijn er verschillende correctieformules bedacht die hier rekening mee proberen te houden. Over het algemeen zijn er twee soort correctieformules voor de ja/nee-test ontwikkeld, het discrete model en het continue model. De eerste soort gaat uit van ‘alles of niets’. Dat betekent dat zij ervan uit gaan dat je een woord wel of niet kent. En als de proefpersoon het antwoord weet, is het correct. Iets er tussenin bestaat niet. De tweede soort, het continue model, houdt wel rekening met de mogelijkheid dat daar iets tussenin zit. Een ander probleem, naast het berekenen van een score, is het de aanwezigheid van een bias in de antwoorden op de test. Er blijkt een omgekeerde relatie te zijn tussen het herkennen van woorden en het verwerpen van pseudowoorden, zoals te zien is in het onderzoek van Beeckmans e.a. (2001). Studenten met een hoge score gaven in dat onderzoek aan veel pseudowoorden te kennen, terwijl juist verwacht werd dat studenten met een hoge score de meeste van de pseudowoorden zou verwerpen. Waarschijnlijk komt dit doordat er een bias in de antwoorden is. De studenten hebben dan een voorkeur voor het antwoord ‘ja’, of het antwoord ‘nee’. Bij een woord waar ze twijfelen wordt er geantwoord met het voorkeursantwoord.
Meara en Buxton (1987) beschrijven een onderzoek naar de ja/nee-test. Daarbij hebben
ze de scores van de ja/nee-test vergeleken met die op een multiple choice test. Daarvoor hadden zij 100 proefpersonen geselecteerd. Beide tests werden op één dag afgenomen met een pauze van 15 minuten tussendoor. Na het afnemen werd er per test een score berekend. Het berekenen van de score werd bij de multiple choice test gedaan door drie punten te geven voor elk goed antwoord en door 1 punt af te trekken bij een fout antwoord. Voor het berekenen van de score op de ja/nee-test is een formule gebruikt van Anderson en Freebody (1983), die er als volgt uit ziet:
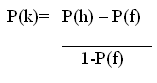
In deze formule wordt het aantal false alarms P(f) afgetrokken van het aantal hits P(h) en gedeeld door 1 min het aantal false alarms. Over deze berekening zijn nog steeds twijfels, zoals verderop in dit hoofdstuk beschreven zal worden. De score op de multiple choice toets wordt berekend door 1 punt te geven voor een goed antwoord en 1 punt af te trekken voor een fout antwoord. Bij de vraag welke van de twee testen de beste is, bleek de ja/nee-test het beste beeld te geven van de vaardigheid van de proefpersonen, aangezien de score op de test overeen kwam met de algemene scores van de proefpersonen op ‘traditionele’ tests.
Een gecomputeriseerde versie van de ja/nee-test werd ontwikkeld door Meara en Jones (1988, 1990) en werd “the Eurocentres Vocabulary Size Test” genoemd. In deze test zijn bestaande woorden en pseudowoorden uit verschillende frequentieniveaus gestopt.
Een ander voorbeeld van een ja/nee-test is de “English as a Foreign Language Vocabulary Test” van Meara (1992b). De EFL vocabulairetest bestaat uit een aantal tests op zes verschillende niveaus, die gebaseerd zijn op woordfrequentie. Het niveau van de eerste test zijn de eerste 1000 meest frequente woorden, het volgende niveau bevat de volgende 1000 woorden enzovoort. Voor elke frequentie zijn er 10 parallelle tests die elk bestaan uit 60 items: 40 bestaande woorden en 20 pseudowoorden.
Het vinden van een juiste correctieformule voor de ja/nee-test blijft een probleem. Bij het berekenen van een score moet namelijk rekening gehouden met 3 punten, volgens Huibregtse, Admiraal en Meara (2001):
1. Bij een yes/no-test zijn er twee soorten goede antwoorden en twee soorten foute antwoorden
2. Proefpersonen hebben de mogelijkheid om te gokken voor het, naar hun mening, beste antwoord.
3. Elke proefpersoon heeft een andere antwoordstijl als hij een antwoord niet weet.
In het artikel van Huibregtse, Admiraal en Meara (2001) wordt een poging gedaan een geschikte manier te vinden om een score te geven op de EFL vocabulairetest. Vier alternatieven worden hiervoor aangeboden, namelijk: “het aantal goede antwoorden”, “correcting for guessing”, Delta M en een nieuwe index die is afgeleid van de Signal Detection Theory (SDT) die is ontwikkeld door Nunnally en Bernstein (1994). Echter bieden al deze vier methodes geen volledige oplossing. In geen van de vier testen kan rekening gehouden worden met alle drie de punten.
De ja/nee-test heeft dus nog enige analyse nodig om optimaal gebruikt te kunnen worden. Vooral op het gebied van het berekenen van de score. En dit is toch wel het belangrijkste component om een onderzoek te kunnen doen. Ook in het artikel van Beeckmans e.a. (2001) houdt men zich bezig met de tekortkomingen van de ja/nee-test. Enkele tekortkomingen die zij noemen zijn:
- het format van de ja/nee-test is niet duidelijk gedefinieerd. Zo staat nergens duidelijk vermeld wat er gedaan moet worden als een proefpersoon ergens vergeet een antwoord te geven.
- Met de test kunnen meerdere betekenissen van een woord niet worden getest.
- Er is weinig aandacht besteed aan de instructie bij de test aan de proefpersonen en de invloed van deze instructie op de proefpersonen.
- Er bestaat geen duidelijke handleiding voor het creëren van pseudowoorden.
- De test kan problemen opleveren voor mensen met (een lichte vorm van) dyslexie.
- De verhouding tussen het aantal bestaande woorden en aantal pseudowoorden varieert per onderzoek, hetgeen de testresultaten zal beïnvloeden.
Zij wijzen op het belang van een goede berekening van een score op de ja/nee-test en in het artikel proberen zij inzicht te bieden in het probleem van het scoren van de ja/nee-test. Het onderzoek in Beeckmans e.a. (2001) bij Franstalige leerders van het Nederlands toonde enkele opvallende dingen. Zo bleek het aantal false alarms hoog te zijn en dit was niet alleen het geval bij zwakke studenten. Ook bleek er een omgekeerde relatie te zijn tussen het herkennen van woorden en het verwerpen van pseudowoorden. Studenten met een hoge score gaven aan veel pseudowoorden te kennen, terwijl juist verwacht werd dat studenten met een hoge score de meeste van de pseudowoorden zou verwerpen. Deze bevindingen leidden tot het onderzoeken van de invloed van de verschillende correctieformules voor de resultaten van de ja/nee-test. Zij concluderen dat deze correctieformules niet geschikt zijn om de ja/nee-test valide te maken aangezien geen van de correctieformules weet om te gaan met de bias in de antwoorden. Tenslotte wijzen zij op de mogelijke invloed van andere factoren, zoals linguïstische, socioculturele, megacognitieve etc., op de grootte van de bias en de rol van de testinstructie hierin.
In Eyckmans (2001) wordt in een onderzoek gekeken naar de invloed van de instructie bij de tests. Ook wordt er gekeken naar de invloed van het aantal false alarms op de betrouwbaarheid van de test. In het onderzoek werden 2 parallelle versies van een ja/nee-test opgesteld en die werden voorgelegd aan 2 groepen proefpersonen. De proefpersonen zijn Franstalige eerstejaarsstudenten handelsingenieur (bedrijfskunde) en economische wetenschappen van de Université Libre de Bruxelles. In de test worden 100 items getest. De ene groep proefpersonen kreeg een neutrale instructie: “Duid met behulp van een kruisje aan welke woorden u kent. Er staan woorden in de lijst die in het Nederlands niet bestaan.” De andere groep proefpersonen kreeg een meer dwingende instructie: “Duid met behulp van een kruisje aan van welke woorden u de betekenis kent. Kruis geen woorden aan waaraan u twijfelt. Pas op! Er staan woorden in de lijst die in het Nederlands niet bestaan. Na deze toets vragen we u de vertaling te geven van enkele woorden uit deze lijst”. Na de ja/nee test moeten de proefpersonen een vertaaltoets maken. Het blijkt dat de meer dwingende instructie bij de ja/nee-test zorgt voor minder false alarms. Toch komt dit de validiteit van de toets niet ten goede. Er is namelijk geen grotere correlatie tussen de vertaaltaak en de ja/nee-test met de meer dwingende instructie dan tussen de vertaaltaak en de ja/nee-test met de neutrale instructie. Eyckmans geeft aan dat er nog onderzocht moet worden of men de false alarmscore op andere manieren kan beïnvloeden, zoals door de selectie van de woorden, woordvormingscriteria voor de pseudowoorden en de omstandigheden waaronder de test wordt afgenomen.
Deze scriptie gaat over het testen van receptieve woordenschatkennis. Hierbij maak ik gebruik van de ja/nee-test van Paul Meara en de pvt-test door middel van een onderzoek. Het doel van mijn onderzoek is een ja/nee-test ontwikkelen voor het Frans en deze testen bij Nederlandstalige studenten. Dit is nog niet gedaan voor het Nederlands. Ook heb ik als doel deze ja/nee-test te valideren. Voor deze scriptie heb ik een experiment gedaan dat bestaat uit 4 delen. Hieronder zal ik per onderdeel beschrijven wat ik heb gedaan en waarom het zo is opgezet.
4.1 Het taalportfolio
Het eerste deel van de test is een “taalportfolio” dat de proefpersonen moeten invullen, zodat ik een beeld van hun kennis van het Frans kan krijgen. Hiervoor heb ik gebruik gemaakt van de site van de Raad van Europa (http://culture2.coe.int/portfolio/). Drie jaar geleden werd het Europese taalportfolio ontwikkeld door de Europese Raad. Het Europees taalportfolio is een document waarin leerders van een taal hun vooruitgang en hun kennis van de taal kunnen bijhouden. In het taalportfolio staat per taal bijgehouden wat de leerder kan. Hiermee wordt getracht leerders van een taal te motiveren. In het algemeen heeft het taalportfolio 2 functies: een pedagogische functie en een documentatie en rapporteerfunctie. Onder de pedagogische functie wordt verstaan: Het motiveren van leerders door het communiceren in verschillende talen mogelijk te maken, extra talen te leren en nieuwe interculturele ervaringen op te doen. Leerders worden aangezet om na te denken over hun doelen en manieren van leren, om hun leeractiviteiten te plannen en om zelfstandig te leren. Ook wordt de meertalige- en interculturele ervaring uitgebreid door bijvoorbeeld contact met mensen uit andere landen, lezen, het gebruik van media en verschillende projecten. Voor de documentatie en rapporteerfunctie zijn verschillende instrumenten ontwikkeld. Bijvoorbeeld een vragenlijst waarin leerders moeten aangeven wat ze wel en niet kunnen in een taal. Verdere voorbeelden zijn te vinden op de site van de Europese Raad. Het taalportfolio biedt door deze instrumenten een beeld van de talenkennis van de leerder, wat zowel makkelijk is voor de leerder als voor bijvoorbeeld een leerling die naar een andere school wil, een sollicitatiegesprek of een talencursus.
Eén van de doelen van het taalportfolio is om mee te helpen bij het beschrijven van vaardigheidsniveaus die vereist worden door bestaande standaarden, tests en toetsen om het vergelijken tussen verschillende systemen en kwalificaties te vergemakkelijken. Een onderdeel dat hieraan tegemoet komt, is een schema dat te zien is in de bijlagen. In het schema zijn er 6 niveaus van vaardigheid. Dit is een interpretatie van de klassieke verdeling in basis, gemiddeld en gevorderd niveau. In het schema zijn dit de niveaus:
- Basis gebruiker: A1 en A2
- Onafhankelijke gebruiker : B1 en B2
- Vaardige gebruiker: C1 en C2
C2 is het hoogste niveau en A1 het laagste. In het schema zijn per niveau en per onderdeel voorbeelden aangegeven van wat de leerder op het betreffende niveau zou moeten kunnen. Aan de hand van dit schema kunnen leerders bepalen op welk niveau ze zich bevinden.
In mijn onderzoek heb ik op het eerste blad van de toets gebruik gemaakt van het bovengenoemde schema. Hierin staan voor drie vaardigheden “ik-kan-beschrijvingen” staan. De drie vaardigheden zijn: begrijpen, spreken en schrijven. Deze staan verdeeld over 6 vaardigheidsniveaus. Voor elke vaardigheid staan 6 blokjes met een beschrijving van wat de student zou kunnen. In de oorspronkelijke tabel staat voor elke blokje een code die het niveau van de vaardigheid van de student aangeeft. Voor mijn onderzoek heb ik deze weggehaald, maar deze zal ik weer gebruiken bij het coderen van de antwoorden. In elke kolom loopt de moeilijkheidsgraad af. De bovenste blokken zijn het moeilijkste en elke blok lager wordt de beheersing van een minder moeilijke vaardigheid beschreven. Bij de tabel heb ik als instructie: “Doorkruis in onderstaande tekst wat je niet kunt in het Frans”. Een voorbeeld van deze eerste pagina is te vinden in de bijlagen.
4.2 De ja/nee-test
De ja/nee-test is gebaseerd op de ja/nee-test van Paul Meara. In dit onderdeel staan er 100 items in kolommen met daarachter de keuzemogelijkheid ja/nee. Hiervan zijn er 60 woorden bestaande Franse woorden en 40 woorden zijn pseudowoorden. Dit zijn woorden die wel voldoen aan de grammaticale- en morfologische regels voor het Frans, maar niet bestaan. Ze zijn gebaseerd op woorden uit de frequentie waarvan ik gebruik maak. De pseudowoorden zijn uitgebreid bekeken om te kijken of ze niet bestaan. Eerst zijn ze opgezocht in de Larousse livre de poche 2003 en de Robert. Vervolgens zijn ze opgezocht op een Franstalige internetpagina met een woordenboekfunctie: http://www.granddictionnaire.com. Tenslotte heeft een native speaker van het Frans de woorden nogmaals bekeken. In tabel 4.1 staat een duidelijk overzicht weergegeven van de verdeling tussen de bestaande Franse woorden en de pseudowoorden.
De bestaande woorden uit de ja/nee-test heb ik gehaald uit een frequentielijst voor het Frans (Juilland 1970). Dit is de meest actuele frequentielijst voor het Frans. Voor het selecteren van de woorden voor de test heb ik een willekeurige selectie gemaakt uit het totaalaanbod woorden tussen de frequentie 0-1000 en 1000-2000. De geselecteerde woorden zijn allemaal zelfstandige naamwoorden en werkwoorden. Verder heb ik erop gelet dat de woorden gelijk zijn verdeeld over de frequentie. Voor beide frequentiebereiken heb ik 60 woorden geselecteerd. Hierdoor zijn twee groepen woorden ontstaan, bestaande uit 60 woorden in de ene groep uit de frequentie 0-1000 en in de tweede groep 60 woorden uit de frequentie 1000-2000. Daarna heb ik vier verschillende versies van de test ontwikkeld waarbij ik de twee groepen woorden kruislings heb gecombineerd in de test zoals staat weergegeven in tabel 2. Versie 1 heeft een ja/nee toets met woorden uit de frequentie 0-1000, terwijl versie 2 woorden bevat uit de frequentie 1000-2000.
Ook heb ik geprobeerd erop te letten dat ik niet ga testen op kennis van de schrijfvaardigheid, door geen minimaal verschil in schrijfwijze van het pseudowoord te laten zijn. De woorden “désir” en “dézir” bijvoorbeeld, lijken qua schrijfwijze teveel op elkaar, waardoor de proefpersoon kan gaan twijfelen over de juiste keuze. In dit eerste onderdeel moeten de proefpersonen aangeven of ze een woord wel of niet kennen door het omcirkelen van hun antwoord. De precieze opdracht die de proefpersonen kregen was “Hieronder zie je een aantal Franse woorden staan. Geef achter de woorden aan of je het woord wel of niet kent. Omcirkel je antwoord. Let op, sommige woorden bestaan niet!”
4.3 De pvt-test
De paired vocabulary test (pvt-test) is een test voor receptieve woordkennis, waarin er geen sprake is van een bias in de antwoorden, zoals in de ja/nee-test. Daar blijkt namelijk dat de proefpersonen een voorkeur hebben voor het antwoord ja of nee, wat de score beïnvloedt, zoals aangetoond door Beeckmans e.a. (2001). In mijn onderzoek heb ik de pvt-test ingevoegd om deze bias te omzeilen
Als de berekening van de score van de ja/nee-test inderdaad twijfelachtig, zoals beschreven in onder andere Beeckmans e.a. (2001) is zal ik dit kunnen aantonen met behulp van de pvt-test, aangezien de scores op de beide testen dan erg zullen verschillen. De pvt-test bestaat uit een lijst met telkens twee woorden en is ontwikkeld door Eyckmans e.a. (2002). In mijn onderzoek heb ik gebruik gemaakt van de ‘kleine pvt-test’, waarin een woord met een daarop lijkend pseudowoord naast elkaar staan. In de ‘gewone pvt-test’ staan een woord en een willekeurig pseudowoord naast elkaar. De pvt-test die ik gebruik in mijn onderzoek heb ik parallel ontworpen aan de ja/nee-test. Ik heb voor beide testen dezelfde items gebruikt, maar het materiaal is gekruisd. Zo is in versie 1a bij de ja/nee-test gebruikt gemaakt van woorden met de frequentie 0-1000 en bij de pvt-test van woorden met de frequentie 1000-2000, terwijl dit in versie 2a is omgekeerd. Daar wordt bij de ja/nee-test gebruikt gemaakt van woorden met de frequentie 1000-2000 en bij de pvt-test van woorden uit de frequentie 0-1000. In tabel 4.2 is een duidelijk overzicht te vinden van deze verdeling bij alle versies. In de test moet er worden gekozen welk van de twee woorden een bestaand Frans woord is. Voor dit onderdeel heb ik 60 bestaande woorden geselecteerd uit de frequentielijst van Juilland en daarbij heb ik 60 pseudowoorden bedacht. Deze pseudowoorden heb ik op het bestaande woord laten lijken. Een voorbeeld hiervan is:
1) dessin - bessin
Ook de pvt-test is opgedeeld in twee versies. Versie 1 heeft een pvt-test met de woorden uit de frequentie 1000-2000, terwijl versie 2 woorden bevat uit de frequentie 0-1000. Om een volgorde-effect te vermijden heb ik versie 1 en versie 2 opgedeeld in a en b, waarbij ik de volgorde van de ja/nee toets en de pvt-test heb omgekeerd.
De opdracht die de proefpersonen kregen was “Er staan telkens twee sterk op elkaar lijkende woorden naast elkaar. Een van de woorden is altijd een bestaand Frans woord, het andere woord bestaat niet in het Frans. Kruis het niet bestaande woord door”.
Na het maken van de twee tests, de ja/nee-test en de pvt-test heb ik een extra vraag toegevoegd. De vraag luidde: Welke van de twee tests (de ja/nee-test of de pvt-test) denk je dat het beste je kennis van het Frans meet? Deze vraag heb ik toegevoegd om te kijken of de studenten zelf een beeld hebben van de tests en de werking daarvan.
4.4 De vertaaltaak
De vertaaltaak bestaat uit 20 woorden uit de groep met de frequentie 0-1000 en 20 woorden uit de groep met woorden uit de frequentie 1000-2000. Deze taak is bij alle vier de versies hetzelfde. De vertaaltaak dient enkel ter validering van de twee andere tests; de ja/nee-test en de pvt-test. Ik kan door de vertaaltaak te gebruiken als valideringstaak, kijken of er een samenhang is tussen de ja/nee-test en de pvt-test.
De vertaaltaak werd gegeven nadat de twee tests zijn gemaakt. Hierbij moeten de proefpersonen bij elk van de 40 items aangeven wat de betekenis van het woord is. Hierbij zijn alle items bestaande Franse woorden. Woorden waarvan de proefpersonen de vertaling niet wisten zijn leeg gelaten. Op het papier dat de proefpersonen kregen stond bij dit onderdeel de volgende opdracht: “Vertaal de volgende Franse woorden naar het Nederlands.” Bij het afnemen van de tests was ik elke keer zelf aanwezig. Uit een vooronderzoek dat ik heb gedaan is namelijk gebleken dat slimme studenten doorhebben dat zij met de woorden uit de vertaaltaak kunnen controleren of zij wel bij bestaande woorden hebben geantwoord dat zij het woord kennen. Ook de pvt-test is zeer makkelijk te verbeteren aan de hand van de vertaaltaak.
Tabel 4.1 De indeling bestaande woorden – pseudowoorden in de drie testen.
|
|
Aantal bestaande woorden |
pseudowoorden |
|
Ja/nee test |
60 |
40 |
|
Pvt-test |
60 |
60 |
|
vertaaltaak |
40 |
0 |
Tabel 4.2 De indeling van de drie testen per versie.
|
Versie |
1e onderdeel test |
2e onderdeel test |
3e onderdeel test |
|
1a |
Ja/nee 0-1000 |
Pvt 1000-2000 |
Vertaaltaak |
|
1b |
Pvt 1000-2000 |
Ja/nee 0-1000 |
Vertaaltaak |
|
2a |
Pvt 0-1000 |
Ja/nee 1000-2000 |
Vertaaltaak |
|
2b |
Ja/nee 1000-2000 |
Pvt 0-1000 |
Vertaaltaak |
4.5 De proefpersonen
In dit onderzoek heb ik gebruik gemaakt van 102 proefpersonen. Alle proefpersonen zijn Nederlandstalige studenten. In Nederland heeft bijna iedereen wel enkele jaren Frans gevolgd. Het aantal jaar dat men Frans heeft gedaan is afhankelijk van de keuze van het studiepakket. Het gevolg is een zeer diverse groep studenten die een verschillende opleiding volgen aan de universiteit en een verschillende leeftijd hebben.
4.6 Doel
Het doel van mijn onderzoek is een ja/nee-test ontwikkelen voor het Frans en deze testen bij Nederlandstalige studenten. Dit is nog niet gedaan voor het Nederlands. Ook heb ik als doel deze ja/nee-test te valideren. Na mijn onderzoek zal ik proberen enkele vragen te beantwoorden:
- Kunnen de proefpersonen met behulp van het taalportfolio een betrouwbaar beeld geven van hun eigen woordkennis?
- Welke van de twee testen (de pvt-test of de ja/nee-test) geeft het beste beeld van de woordkennis van de studenten?
In totaal hebben 102 proefpersonen aan dit onderzoek meegewerkt en alle tests gemaakt. Het aantal personen dat een test heeft gemaakt heb ik niet voor iedere test gelijk kunnen krijgen. In onderstaande tabel is te zien hoe de verdeling van de proefpersonen precies is over de versies.
Tabel 5.1 Verdeling aantal proefpersonen over de versies.
|
Versie |
N |
|
1a |
27 |
|
1b |
22 |
|
2a |
27 |
|
2b |
26 |
5.1 Het taalportfolio
De antwoorden van de proefpersonen heb ik per kolom bekeken. Oorspronkelijk staat er voor elke regel van het taalportfolio het niveau weergeven. De kolommen zijn aflopend wat betreft moeilijkheidsgraad. In SPSS heb ik per proefpersoon per kolom weergegeven wat het hoogste niveau is wat de proefpersoon kan. Dit is het 1e vakje in de kolom (van bovenaf) dat niet is doorkruist. In onderstaande tabel is te zien wat de proefpersonen aangaven te kunnen. In het schema is te zien dat er ook mensen zijn die aangeven niets te kunnen.
Tabel 5.2 Niveauverdeling per deelvaardigheid in het taalportfolio.
|
|
A Begrijpen |
B Begrijpen |
A Spreken |
B Spreken |
Schrijven |
|
|
|
Niveau C2 |
1 |
1 |
1 |
1 |
1 |
|
|
Niveau C1 |
4 |
1 |
0 |
0 |
5 |
|
|
Niveau B2 |
18 |
39 |
7 |
11 |
11 |
|
|
Niveau B1 |
46 |
36 |
23 |
34 |
32 |
|
|
Niveau A2 |
22 |
20 |
45 |
32 |
30 |
|
|
Niveau A1 |
7 |
4 |
22 |
16 |
18 |
|
|
Niets |
4 |
1 |
4 |
8 |
5 |
|
|
Totaal |
102 |
102 |
102 |
102 |
102 |
Vervolgens heb ik drie groepen proefpersonen gemaakt die ik heb gebaseerd op hun gemiddelde niveau voor de verschillende vaardigheden. Helemaal gelijke groepen zijn niet te vormen, vandaar dat ik de meest gelijke groep heb gevormd. Hiervoor heb ik eerst voor elk proefpersoon het gemiddelde niveau bepaald door per proefpersoon de vaakst gebruikte niveauaanduiding te nemen als het algemene niveau van de proefpersoon. Vervolgens heb ik een verdeling gemaakt in drie groepen. Groep 3 bestaat uit proefpersonen die aangeven een gemiddeld niveau van B2 of hoger te hebben. Groep 2 bestaat uit proefpersonen die aangeven de vaardigheden op een gemiddeld niveau van B1 te kunnen doen en groep 1 bestaat uit mensen die aangeven een gemiddeld niveau van A2 of lager te hebben. In totaal ziet de verdeling van de proefpersonen over de niveaus er als volgt uit:
Tabel 5.3 Groepsverdeling in het taalportfolio.
|
Groep |
N |
% |
|
|
|
1 |
25 |
24,5 |
|
|
2 |
43 |
42,2 |
|
|
3 |
34 |
33,3 |
|
|
Totaal |
102 |
100,0 |
5.2 De ja/nee-test
De resultaten van de ja/nee-test heb ik samengevat in figuur 5.2 dat overzichtelijk informatie biedt over de verdeling van alle antwoorden opgedeeld in hit, miss, false alarm en correct rejection. (Beeckmans e.a. 2001). In de rij “woord” staat in de kolom “ja” het aantal hits weergegeven en in de kolom ernaast, bij “nee” staat het aantal miss. In de rij “pseudowoord” staat in de eerste kolom het aantal false alarms en in de tweede kolom het aantal correct rejections. In figuur 5.3 is hiervan een overzicht te vinden. Bij alle weergaves van de aantallen antwoorden staan het afgeronde percentage weergegeven, zodat een goed totaalbeeld geboden kan worden. Bij het berekenen van de totalen per versie heb ik rekening gehouden met “missing values” door alleen gebruik te maken van alle antwoorden die ik wel had en de ontbrekende antwoorden buiten beschouwing te laten.
Figuur 5.2 Antwoordmodel voor de ja/nee-test.
Figuur 5.3 Verdeling hits, miss, false alarms en correct rejections.
|
versie 1a |
|
|
|
versie 1b |
|
|
|
|
Ken je het woord ? |
|
|
Ken je het woord ? |
||
|
|
Ja |
Nee |
|
|
Ja |
Nee |
|
Woord |
1383 (85,4%) |
236 (14,6%) |
|
Woord |
1050 (79,5%) |
271 (20,5%) |
|
Pseudowoord |
117 (10,8%) |
962 (89,2%) |
|
Pseudowoord |
64 (7,3%) |
815 (92,7%) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
versie 2a |
|
|
|
versie 2b |
|
|
|
|
Ken je het woord ? |
|
|
Ken je het woord ? |
||
|
|
Ja |
Nee |
|
|
Ja |
Nee |
|
Woord |
852 (75,9%) |
271 (24,1%) |
|
Woord |
892 (57,2%) |
668 (42,8%) |
|
Pseudowoord |
86 (8%) |
994 (92%) |
|
Pseudowoord |
106 (10,2%) |
933 (89,8%) |
Uit bovenstaande tabellen blijkt dat versie 1a en 1b bestaande woorden iets vaker worden herkend. Bij deze versies ligt dat rond de 80%. Bij versie 2a en 2b liggen de percentages bij de hits iets lager. Dit is bij versie 2a op 75,9% en bij versie 2b 57,2%. Het percentage false alarms van versie 1b en 2a liggen allebei rond de 8%, terwijl bij de versies 1a en 2b dit percentage rond de 10% ligt.
In onderstaande tabel staat samengevat welke woorden iedereen herkent in de ja/nee-test en welke pseudowoorden door iedereen werden herkend als niet bestaand. Bij de bestaande woorden blijkt dat alleen de woorden uit de ja/nee-test met de selectie uit de frequentie 0-1000 worden herkend. Wat opvalt is dat de frequentienummers van de woorden die door iedereen worden herkend verspreid liggen over het frequentiebereik 0-1000 en niet allemaal afkomstig zijn uit de eerste 100 woorden uit de frequentie. De pseudowoorden blijken voor de tests met de woorden uit de frequentie 0-1000 en de tests met woorden uit de frequentie 1000-2000 even moeilijk/ makkelijk te zijn geweest. In beide tests zijn evenveel pseudowoorden door iedereen verworpen. In zowel de test met frequenties van 0-1000 als in de test met frequenties van 1000-2000 is dat 8 woorden van de 40 pseudowoorden in totaal.
Tabel 5.4 Frequenties van woorden die 100% aangegeven worden gekend te zijn en pseudowoorden die 100% verworpen worden.
|
Freqnr. |
Woorden 100% antwoord ‘ja’. |
|
Pseudowoorden 100% antwoord ‘nee’. |
|
|
|
Freq. 0-1000 |
|
Freq.0-1000 |
Freq. 1000-2000 |
|
70 |
homme |
|
asuge |
bouffler |
|
245 |
suite |
|
catère |
catoirie |
|
519 |
départ |
|
dalin |
coiter |
|
557 |
voyage |
|
doin |
coursance |
|
891 |
montagne |
|
résamé |
dauter |
|
|
|
|
toible |
menoce |
|
|
|
|
voeloir |
pontin |
|
|
|
|
bépris |
remplar |
In de onderstaande tabel staan de overige woorden en pseudowoorden uit de ja/nee-test beschreven. De pseudowoorden heb ik wel onderverdeeld in de frequentie 0-1000 en 1000-2000, door ze bij de frequentie te zetten van de testversie waarin ze gebruikt zijn. Ze staan aflopend naar de mate waarop ze aangegeven worden gekend te zijn door de proefpersonen. De pseudowoorden daarna zijn door veel minder proefpersonen aangegeven als bekend. Hier begint het percentage proefpersonen dat ja zegt bij een pseudowoord met 46,9%. Toch is het percentage ja-antwoorden bij de pseudowoorden erg hoog. Helemaal gezien het feit dat eigenlijk alle pseudowoorden verworpen zouden moeten worden in plaats van de 17 pseudowoorden die nu verworpen zijn. Daaruit blijkt duidelijk dat er een bias in de antwoorden moet zijn. De proefpersonen lijken een voorkeur voor één van de twee antwoorden (ja of nee) te hebben. In geval van twijfel, of wanneer zij een woord niet kennen, beantwoorden zij de vraag met hun voorkeursantwoord.
Tabel 5.5 Percentages woorden en pseudowoorden gekend in de ja/nee-test.
|
Woorden |
|
Pseudowoorden |
||||||
|
Freq. 0-1000 |
Freq. 1000-2000 |
|
Freq. 0-1000 |
Freq. 1000-2000 |
||||
|
woord |
% gekend |
woord |
% gekend |
|
woord |
% gekend |
woord |
% gekend |
|
départ |
100 |
exposer |
98,1 |
|
morter |
46,9 |
doir |
43,4 |
|
homme |
100 |
lait |
96,2 |
|
batter |
38,8 |
sommettre |
26,4 |
|
montagne |
100 |
décision |
92,5 |
|
décidre |
38,8 |
victoirer |
26,4 |
|
suite |
100 |
réflexion |
92,5 |
|
morder |
22,4 |
aventer |
20,8 |
|
voyage |
100 |
chapeau |
88,7 |
|
paison |
20,4 |
chamoix |
20,8 |
|
continuer |
98 |
composer |
88,7 |
|
poucher |
20,4 |
hours |
17 |
|
écouter |
98 |
exécuter |
88,7 |
|
anfin |
18,4 |
pirer |
17 |
|
être |
98 |
solution |
88,7 |
|
amoir |
14,3 |
beçon |
15,1 |
|
marcher |
98 |
soirée |
84,9 |
|
rachir |
14,3 |
demuser |
15,1 |
|
monde |
98 |
engager |
83 |
|
savier |
14,3 |
dommer |
13,2 |
|
prendre |
98 |
quantité |
83 |
|
charder |
12,2 |
emploition |
13,2 |
|
soleil |
98 |
banque |
81,1 |
|
dousser |
10,2 |
choleur |
11,3 |
|
temps |
98 |
dessin |
81,1 |
|
pari |
10,2 |
clatte |
11,3 |
|
trouver |
98 |
quart |
81,1 |
|
dentiment |
8,2 |
domanche |
11,3 |
|
ville |
98 |
rire |
81,1 |
|
sépéner |
8,2 |
mainte |
11,3 |
|
visage |
98 |
couper |
77,4 |
|
tanir |
8,2 |
mêloir |
11,3 |
|
vivre |
98 |
dommage |
75,5 |
|
janter |
6,1 |
matelier |
9,4 |
|
ami |
95,9 |
lune |
75,5 |
|
noige |
6,1 |
ploirer |
9,4 |
|
avoir |
95,9 |
naissance |
71,7 |
|
vassage |
6,1 |
viandi |
9,4 |
|
boire |
95,9 |
durée |
69,8 |
|
bâche |
4,1 |
méduire |
7,5 |
|
chanter |
95,9 |
équilibre |
69,8 |
|
humérer |
4,1 |
pertu |
7,5 |
|
coup |
95,9 |
délivrer |
67,9 |
|
meuver |
4,1 |
franter |
5,7 |
|
fleur |
95,9 |
éclat |
67,9 |
|
poi |
4,1 |
cammondir |
3,8 |
|
table |
95,9 |
promettre |
67,9 |
|
risite |
4,1 |
lomer |
3,8 |
|
annoncer |
93,9 |
désir |
66 |
|
bortoir |
2 |
ostamer |
3,8 |
|
laisser |
93,9 |
mentir |
66 |
|
deure |
2 |
pache |
3,8 |
|
travail |
93,9 |
réclamer |
66 |
|
étase |
2 |
rommage |
3,8 |
|
dire |
91,8 |
trésor |
64,2 |
|
litte |
2 |
soumage |
3,8 |
|
jeu |
91,8 |
statue |
62,3 |
|
mester |
2 |
traquerir |
3,8 |
|
vie |
89,8 |
jugement |
58,5 |
|
moiture |
2 |
ravue |
1,9 |
|
été |
87,8 |
miroir |
54,7 |
|
rampagne |
2 |
dolonie |
1,9 |
|
parti |
87,8 |
destin |
50,9 |
|
troville |
2 |
bépris |
0 |
|
séparer |
87,8 |
mesurer |
50,9 |
|
vou |
2 |
bouffler |
0 |
|
argent |
85,7 |
ressource |
50,9 |
|
asuge |
0 |
catoirie |
0 |
|
bouche |
85,7 |
tapis |
49,1 |
|
catère |
0 |
coiter |
0 |
|
maintenir |
85,7 |
sommeil |
47,2 |
|
dalin |
0 |
coursance |
0 |
|
main |
83,7 |
interrompre |
41,5 |
|
doin |
0 |
dauter |
0 |
|
montrer |
83,7 |
sonner |
41,5 |
|
résamé |
0 |
menoce |
0 |
|
revoir |
81,6 |
troubler |
39,6 |
|
toible |
0 |
pontin |
0 |
|
âge |
79,6 |
allonger |
37,7 |
|
voeloir |
0 |
remplar |
0 |
|
lit |
79,6 |
enfance |
37,7 |
|
|
|
|
|
|
observer |
79,6 |
tendresse |
37,7 |
|
|
|
|
|
|
poursuivre |
79,6 |
fuir |
35,8 |
|
|
|
|
|
|
ciel |
73,5 |
genou |
32,1 |
|
|
|
|
|
|
confiance |
73,5 |
haine |
32,1 |
|
|
|
|
|
|
peau |
73,5 |
laine |
30,2 |
|
|
|
|
|
|
perdre |
71,4 |
soulever |
28,3 |
|
|
|
|
|
|
peur |
71,4 |
taire |
28,3 |
|
|
|
|
|
|
tromper |
71,4 |
colline |
26,4 |
|
|
|
|
|
|
besoin |
69,4 |
partager |
26,4 |
|
|
|
|
|
|
éviter |
69,4 |
tenter |
22,6 |
|
|
|
|
|
|
réfléchir |
65,3 |
témoigner |
20,8 |
|
|
|
|
|
|
valeur |
59,2 |
vertu |
20,8 |
|
|
|
|
|
|
but |
57,1 |
aborder |
18,9 |
|
|
|
|
|
|
mesure |
57,1 |
heurter |
18,9 |
|
|
|
|
|
|
oeil |
53,1 |
serrer |
17 |
|
|
|
|
|
|
douter |
30,6 |
coutume |
15,1 |
|
|
|
|
|
|
cesser |
28,6 |
lutter |
15,1 |
|
|
|
|
|
|
plaire |
26,5 |
aboutir |
13,2 |
|
|
|
|
|
|
songer |
24,5 |
nier |
13,2 |
|
|
|
|
|
5.3 De Pvt-test
Bij deze toets was het niet nodig om 4 scores te geven, aangezien er maar twee antwoordmogelijkheden zijn. Bij de pvt-test heb ik met de cijfers 1 en 2 gewerkt om de antwoorden van de proefpersonen te coderen. Dit heb ik gedaan door de code 1 te geven als de proefpersoon een bestaand Frans woord als goed weergaf in de test (door deze niet door te kruisen). Als de proefpersoon een pseudowoord als goed beschouwde, heb ik de code 2 gegeven. In de onderstaande tabel staan de resultaten uitgewerkt.
Figuur 5.4 Verdeling goede en foute antwoorden op de pvt-test
|
versie 1a |
(N=27) |
|
versie 1b |
(N=22) |
|
Goed |
Fout |
|
Goed |
Fout |
|
1361 (84,01%) |
250 (15,43%) |
|
1115 (84,47%) |
203 (15,38%) |
|
|
|
|
|
|
|
versie 2a |
(N=27) |
|
versie 2b |
(N=26) |
|
Goed |
Fout |
|
Goed |
Fout |
|
1466 (90,49%) |
150 (9,26%) |
|
1443 (92,50%) |
113 (7,24%) |
De pvt-test wordt duidelijk zeer goed gemaakt door iedereen, waardoor een plafondeffect wordt veroorzaakt. Het verschil tussen de selectie van de woorden uit de verschillende frequentieniveaus is ook hier goed te zien. Versies 1a en 1b hadden een pvt-test met woorden uit de frequentie 1000-2000 en de versies 2a en 2b hadden woorden uit de frequentie 0-1000. Tussen versie 1a en 1b is er zeer weinig verschil, net als tussen de versies 2a en 2b.
5.4 De vertaaltaak
Voor dit deel van de test heb ik alle antwoorden die de proefpersonen gegeven hebben ingevoerd in Excel. Hierna heb ik alle antwoorden nagekeken. Door middel van een sorteeropdracht per woord heb ik voorkomen dat er verschillen zaten in de score die ik voor het woord gaf. Ik heb goede vertalingen de code 1 gegeven en foute vertalingen, en waar niets is ingevuld, een code 2. In totaal werden er 2459 (60,3%) goede antwoorden gegeven en 1621 (39,7%) foute antwoorden. De woorden waarvan bijna iedereen de betekenis kent zijn:
Tabel 5.6 Woorden door bijna iedereen goed
|
Woord |
Frequentie |
Percentage proefpersonen dat een goed antwoord heeft gegeven. |
|
homme |
70 |
98 |
|
solution |
1055 |
98 |
|
ami |
217 |
97,1 |
|
table |
335 |
96,1 |
|
fleur |
480 |
95,1 |
|
décision |
1872 |
95,1 |
Tabel 5.7 Woorden door bijna iedereen fout.
|
Woord |
Frequentie |
Percentage proefpersonen dat een fout antwoord heeft gegeven. |
|
songer |
416 |
99 |
|
nier |
1928 |
90,2 |
Bij het vergelijken van deze twee groepen woorden valt op dat het woord songer door bijna niemand wordt gekend, terwijl het een woord is met een vrij hoge frequentie. De woorden solution en décision worden juist wel gekend door bijna alle proefpersonen, terwijl deze woorden een lagere frequentie hebben. Een aannemelijke verklaring is dat het woord songer niet lijkt op een woord in een taal die wel bekend kan zijn bij de proefpersonen zoals het Engels of het Nederlands. Solution en décision verschillen qua uitspraak van het Engels, maar de schrijfwijze en de betekenis komen overeen. In het Engels zijn deze woorden vrij frequent en daarom kennen de meeste proefpersonen de woorden wel via het Engels.
6.1 De resultaten
Het taalportfolio bestaat uit 3 groepen. In tabel 6.1 is te zien hoe deze zich verhouden tot de andere onderdelen van de test. Te zien is dat het gemiddelde van groep 3 voor alle drie de tests het hoogst is. Ook is de standaard deviatie voor groep 3 bij de pvt-test en de ja/nee-test het laagst. Dit is een goed teken aangezien groep 3 bestaat uit de proefpersonen die bij het taalportfolio aangaven een niveau van B2 of hoger te hebben. Bij het vergelijken van de drie groepen van het taalportfolio met behulp van een variantie-analyse blijkt dat de groepen duidelijk van elkaar onderscheiden kunnen worden. Het taalportfolio is dus een duidelijke en makkelijke manier om een eerste inschatting te maken van het niveau van de proefpersonen.
Zoals beschreven in hoofdstuk 3 zijn er verschillende formules om de score op de ja/nee-test te berekenen. Ik zal voor het berekenen van de score op de ja/nee-test in mijn onderzoek 4 verschillende formules naast elkaar zetten om te kijken welke van deze vier formules het beste correleert met de score op de pvt-test en het aantal goede antwoorden bij de vertaaltaak. De vier formules waarnaar ik zal kijken zijn:
Delta M (Meara, 1992c). In deze formule wordt er rekening gehouden met het aantal hits dat de proefpersonen zouden hebben als ze geen ja zouden hebben gezegd bij één van de pseudowoorden. De formule ziet er als volgt uit:
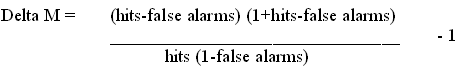
Correction for guessing (CFG) (Nunnally en Bernstein, 1994). Bij deze formule wordt er van twee mogelijkheden voor elk item uit gegaan. Of de proefpersoon kent het woord, of de persoon kent het woord niet en gokt willekeurig. Dit wordt ook wel een correctieformule volgens het discrete model genoemd. Van de vier verschillende correctieformules die ik gebruik om een score op de ja/nee-test te berekenen, is dit de enige test die binnen het discrete model valt. De andere testen behoren tot het continue model. De formule is dan 1 gedeeld door het aantal antwoorden. Omdat er ook rekening gehouden moet worden met false alarms wordt de formule:
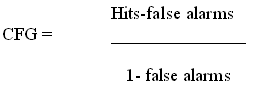
Hits Corrected for Bias (HCFB) is een formule waarin er ook rekening gehouden wordt met het gokken van de proefpersonen. De HCFB is een gecorrigeerde versie van de ISDT, met als toevoeging dat er bij de HCFB geprobeerd wordt de bias niet te meten.
ISDT is gebaseerd op de Signal Detection Theory (SDT) en deze nieuwe formule wordt geïntroduceerd in Huibregtse e.a. (2001). In de ISDT-formule wordt er vanuit gegaan dat als een proefpersoon twijfelt bij een antwoord op de ja/nee-test, hij zal kiezen voor “ja”. De formule ziet er als volgt uit:
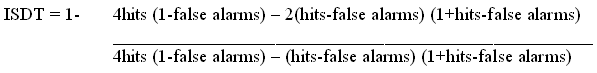
Zoals te zien is in tabel 6.2 correleert de formule HCFB het beste met de pvt-test, terwijl de ISDT juist het beste correleert met de vertaaltaak, al is de correlatie van de HCFB niet veel lager. Voor deze tabel heb ik gebruik gemaakt van een gecorrigeerde versie van de pvt-test, die ik heb berekend door voor elke fout 1 punt af te trekken, en ik heb deze nieuwe versie PVT2 genoemd. Uit recent onderzoek van Beeckmans e.a. (2001) blijkt dat daar de CFG het beste correleert, terwijl in mijn onderzoek deze formule juist het slechtste werkt. De CFG correleert bij mij het slechtst, zowel met de PVT als met de vertaaltaak. Uiteindelijk meten alle 4 de gebruikte formules voor de ja/nee-test toch nog de bias. Er moet dus een nieuwe formule uitgevonden worden die de bias niet meet.
Tabel 6.1 Resultaten op de testen en vertaaltaak per groep van het taalportfolio
|
|
|
Niveau |
N |
Gemiddelde |
Std. Deviatie |
|
|
DELTA M |
1 |
25 |
13,36 |
18,304 |
|
|
|
2 |
43 |
29,37 |
16,422 |
|
|
|
3 |
34 |
44,27 |
11,258 |
|
|
|
Total |
102 |
30,42 |
19,242 |
|
Ja-nee |
HCFB |
1 |
25 |
30,1715 |
10,34378 |
|
(60) |
|
2 |
43 |
39,2757 |
10,07019 |
|
|
|
3 |
34 |
48,0304 |
7,57217 |
|
|
|
Total |
102 |
39,9625 |
11,49649 |
|
|
ISDT60 |
1 |
25 |
27,4141 |
9,53768 |
|
|
|
2 |
43 |
36,6860 |
10,26467 |
|
|
|
3 |
34 |
46,7655 |
8,33891 |
|
|
|
Total |
102 |
37,7733 |
11,93467 |
|
|
CFG60 |
1 |
25 |
26,1825 |
12,99746 |
|
|
|
2 |
43 |
38,1291 |
13,29120 |
|
|
|
3 |
34 |
49,6216 |
9,45602 |
|
|
|
Total |
102 |
39,0318 |
14,89245 |
|
PVT |
PVT2 |
1 |
25 |
34,96 |
9,817 |
|
(60) |
|
2 |
43 |
46,14 |
8,927 |
|
|
|
3 |
34 |
52,71 |
6,785 |
|
|
|
Total |
102 |
45,59 |
10,781 |
|
Vertaaltaak |
goed vertaaltaak |
1 |
25 |
16,56 |
5,324 |
|
(40) |
|
2 |
43 |
23,44 |
5,679 |
|
|
|
3 |
34 |
30,50 |
6,111 |
|
|
|
Total |
102 |
24,11 |
7,771 |
Tabel 6.2 Correlaties ja/nee-test, pvt-test en vertaaltaak en taalportfolio
|
|
|
TOTAALTP |
DELTA M |
ISDT60 |
CFG60 |
HCFB |
PVT2 |
goed vertaaltaak |
|
Taalportfolio |
TOTAALTP |
|
,615 |
,622 |
,622 |
,592 |
,608 |
,684 |
|
|
DELTAM2 |
,615 |
|
,991 |
,918 |
,976 |
,330 |
,642 |
|
Ja-nee |
ISDT60 |
,622 |
,991 |
|
,927 |
,973 |
,336 |
,655 |
|
|
CFG60 |
,622 |
,918 |
,927 |
|
,838 |
,287 |
,616 |
|
|
HCFB |
,592 |
,976 |
,973 |
,838 |
|
,364 |
,653 |
|
PVT |
PVT2 |
,608 |
,330 |
,336 |
,287 |
,364 |
|
,758 |
|
Vertaaltaak |
goed vertaaltaak |
,684 |
,642 |
,655 |
,616 |
,653 |
,758 |
|
Ook is in tabel 6.2 te zien dat hoewel de pvt-test plafonneert, deze test de hoogste correlatie heeft met de vertaaltaak. Er is een correlatie van .758 en dat is hoger dan de correlatie op de ja/nee-test, ongeacht de soort formule. Alle discussies over de verschillende correctieformules zijn naar mijn idee dan ook niet nodig. Het blijkt uit mijn data duidelijk dat de gebruikte formules voor de ja/nee-test niet werken. De correlatie van .758 tussen de score op de pvt-test en de vertaaltaak wil zeggen dat de score op de pvt-test voor 57,4 % samenhangen met de scores op de vertaaltaak. Proefpersonen die veel goede antwoorden geven bij de pvt-test hebben ook een hoge score op de vertaaltaak. De score van de pvt-test correleert zwak met de scores van de ja/nee-test, ongeacht de formule. Dit is zeer opmerkelijk, aangezien de pvt-test en de ja/nee-test parallel zijn ontworpen en dus een hoge correlatie zouden moeten hebben. Bij het taalportfolio heb ik een totaalscore berekend per leerling. Voor elk niveau heb ik een aantal punten gegeven en deze punten heb ik voor de 5 verschillende onderdelen van het taalportfolio (begrijpen A en B, spreken A en B en schrijven) toegekend. Dit heb ik als volgt gedaan:
|
Niveau |
punten |
|
C2 |
7 |
|
C1 |
6 |
|
B2 |
5 |
|
B1 |
4 |
|
A2 |
3 |
|
A1 |
2 |
|
Niets ingevuld |
1 |
De totaalscore per proefpersoon is de score per onderdeel bij elkaar opgeteld. Hiermee wordt de hoogste totaalscore voor het taalportfolio 5x7 = 35 en de laagste score is 5x1 = 5. De correlatie met de andere tests is berekend met behulp van deze totaalscore voor het taalportfolio. De correlatie van de ja/nee-test, de pvt-test en de vertaaltaak met het taalportfolio is ongeveer gelijk.
Vervolgens heb ik gekeken naar een ander punt bij de ja/nee-test. Ik heb gekeken of er ook mensen zijn die bij de ja/nee-test zeggen een woord niet te herkennen en vervolgens dit woord wel goed kunnen vertalen bij de vertaaltaak en mensen die een woord zeggen wel te herkennen, maar dit woord niet kunnen vertalen bij de vertaaltaak. Het blijkt dat er een heleboel van dit soort gevallen zijn. In tabel 6.3 en 6.4 is te zien hoe vaak dat gebeurt. Hier gebruik ik 20 woorden aangezien de woorden uit de vertaaltaak verdeeld komen uit de beide frequentiebereiken die ik heb gebruikt. Ik heb 20 woorden uit de frequentie 0-1000 en 20 woorden uit de frequentie 1000-2000 gebruikt. Vooral opmerkelijk is dat er mensen zijn die zeggen een woord niet te herkennen bij de ja/nee-test, maar toch de betekenis weten als het woord gevraagd wordt bij de vertaaltaak. Zeer opvallend is ook dat in tabel 6.3 een aantal woorden slechts door enkele proefpersonen fout wordt beantwoord op de ja/nee-test, maar vervolgens toch goed worden vertaald in de vertaaltaak. Zo wordt ‘ami’ door 2 mensen niet herkend op de ja/nee-test (miss), maar weten diezelfde 2 mensen wel het goede antwoord te geven op de vertaaltaak. Hetzelfde gebeurt bij de woorden ‘chanter’, ‘être’, ‘fleur’, ‘marcher’ en ‘table’. In tabel 6.4 is te zien dat de verschillen tussen hits en miss kleiner worden en dat de getallen dichter bij elkaar komen te liggen voor een woord. Een verklaring voor het hoge aantal miss is het feit dat de proefpersonen zich overschatten. Ook nu is het weer bij een paar woorden het geval dat slechts enkele proefpersonen zeggen het woord niet te herkennen bij de ja/nee-test, maar weten diezelfde mensen bij de vertaaltaak toch de juiste vertaling van het woord te geven. Dit gebeurt bij de woorden ‘décision’, ‘réflexion’ en ‘solution’. Een verklaring hiervan kan zijn dat de betreffende proefpersonen bij deze woorden twijfelden op de ja/nee-test en hebben zij een voorkeur voor het antwoord nee. Dit zou dan een duidelijk voorbeeld van de bias in de antwoorden zijn.
Tabel 6.3 Aantal niet-eenduidige antwoorden op de ja/nee-test in de frequentie 0-1000
|
N=49 |
‘ja' op ja/nee-test en geen goede vertaling |
‘nee' op ja/nee-test en wel goede vertaling |
hit |
miss |
|
|
|
|
|
|
|
ami |
0 |
2 |
47 |
2 |
|
bouche |
27 |
3 |
42 |
7 |
|
but |
14 |
8 |
28 |
21 |
|
chanter |
8 |
2 |
47 |
2 |
|
douter |
9 |
7 |
15 |
34 |
|
être |
4 |
1 |
48 |
1 |
|
fleur |
3 |
2 |
47 |
2 |
|
homme |
1 |
0 |
49 |
0 |
|
maintenir |
22 |
2 |
42 |
7 |
|
marcher |
7 |
1 |
48 |
1 |
|
montagne |
7 |
0 |
49 |
0 |
|
montrer |
27 |
2 |
41 |
8 |
|
peau |
15 |
7 |
36 |
13 |
|
perdre |
12 |
8 |
35 |
14 |
|
songer |
12 |
0 |
12 |
36 |
|
table |
3 |
2 |
47 |
2 |
|
tromper |
28 |
5 |
35 |
14 |
|
valeur |
11 |
11 |
29 |
20 |
|
vie |
5 |
4 |
44 |
5 |
|
visage |
18 |
0 |
48 |
1 |
|
Totaal |
233 |
67 |
|
|
Tabel 6.4 Aantal niet-eenduidige antwoorden op de ja/nee-test in de frequentie 1000 -2000
|
N=53 |
‘ja' op ja/nee-test en geen goede vertaling |
‘nee' op ja/nee-test en wel goede vertaling |
hit |
miss |
|
|
|
|
|
|
|
couper |
9 |
3 |
41 |
11 |
|
décision |
3 |
4 |
49 |
4 |
|
désir |
2 |
9 |
35 |
18 |
|
dommage |
6 |
1 |
40 |
13 |
|
équilibre |
18 |
0 |
37 |
16 |
|
fuir |
10 |
1 |
19 |
34 |
|
genou |
5 |
1 |
17 |
36 |
|
lune |
3 |
6 |
40 |
12 |
|
miroir |
5 |
9 |
29 |
24 |
|
naissance |
5 |
1 |
38 |
15 |
|
nier |
2 |
2 |
7 |
46 |
|
promettre |
5 |
4 |
36 |
17 |
|
quantité |
2 |
5 |
44 |
9 |
|
réflexion |
3 |
4 |
49 |
4 |
|
rire |
3 |
4 |
43 |
10 |
|
solution |
0 |
6 |
47 |
6 |
|
sommeil |
12 |
1 |
25 |
28 |
|
sonner |
8 |
0 |
22 |
31 |
|
taire |
8 |
3 |
15 |
38 |
|
trésor |
7 |
7 |
34 |
19 |
|
Totaal |
116 |
71 |
|
|
6.2 Conclusie
Het taalportfolio blijkt wel een goed beeld te geven van de kennis van de proefpersonen. Er blijkt een correlatie te zijn tussen de score op het taalportfolio en de pvt-test en de ja/nee-test. Dit wil zeggen dat mensen die bij het taalportfolio zeggen goed te zijn in bepaalde delen van een taal ook een goede score hebben op de twee woordenschattests. Het antwoord op mijn eerste vraag bij dit onderzoek, kunnen de proefpersonen met behulp van het taalportfolio een betrouwbaar beeld geven van hun eigen woordkennis, moet ik dus beantwoorden met ja.
De tweede vraag die ik probeerde te beantwoorden in dit onderzoek is: Welke van de twee testen (de pvt-test of de ja/nee-test) geeft het beste beeld van de woordkennis van de studenten? Om deze vraag te kunnen beantwoorden heb ik de ja/nee-test en de pvt-test naast elkaar gezet om te kijken of er een verschil is in de samenhang tussen de twee testen en de vertaaltaak. Het blijkt dat de pvt-test de hoogste correlatie heeft met de vertaaltaak, wat wil zeggen dat de pvt-test een betrouwbaarder beeld geeft van de kennis van de leerling. Er is dus wel degelijk één test beter dan de ander. Dit komt naar mijn idee voornamelijk doordat er nog steeds geen goede formule is om de score te berekenen op de ja/nee-test, die rekening houdt met alle moeilijkheden van de ja/nee-test, zoals de twee verschillende soorten goede antwoorden, de mogelijkheid om te gokken op de test en de bias in de antwoorden. In totaal gaven 58 proefpersonen na het maken van de ja/nee-test en de pvt-test aan dat zij dachten dat de pvt-test het beste beeld gaf van hun woordenschatkennis, terwijl 34 proefpersonen dachten dat juist de ja/nee-test een beter beeld gaf. De overige 10 proefpersonen hebben niets bij de vraag ingevuld of gaven aan geen mening hierover te hebben.
Dit onderzoek is ook zeer belangrijk voor het talenonderwijs. Het testen van woordkennis gebeurt daar regelmatig en een test die een goed beeld kan geven van de receptieve woordkennis van studenten is zeer handig. Kennis van de receptieve woordenschat van taalleerders is o.a. zeer van belang voor leesvaardigheid. Hoe meer woorden men receptief kent, hoe beter moeilijkere teksten gelezen kunnen worden. Door de pvt-test kan hiervoor het niveau worden geschat. Dit kan bijvoorbeeld handig zijn om een inschatting te maken van het niveau van een leerling die van de ene school naar de andere school gaat. Ook kan hiermee een gekeken worden of de leerling een achterstand heeft of juist een voorsprong op de rest van de klas en eventueel extra onderwijs nodig heeft. Zowel de ja/nee-test als de pvt-test heeft belangrijke voordelen ten opzichte van reeds gebruikte tests om woordkennis te testen, zoals:
- het ontwikkelen van de test neemt niet veel tijd in beslag
- het invullen van een ja/nee-test neemt niet veel tijd in beslag
- het testen van een groter aantal items is daardoor mogelijk
- de test kan hierdoor een beter beeld geven van de totale woordkennis, wat bij de multiple choice tests niet het geval was. Deze zijn vooral effectief bij het testen van woordkennis op een lager vaardigheidsniveau.
Voor de ja/nee-test is er echter nog geen goede manier gevonden om de score te berekenen, waardoor er met behulp van deze test nog geen betrouwbaar beeld gegeven kan worden van de kennis van een leerling. De pvt-test daarentegen heeft wel een eenvoudige en goede manier om de score op deze test te berekenen. Ook heeft de test, zoals gebleken is uit mijn onderzoek, een betere samenhang met de vertaaltaak hetgeen laat zien dat de test een betrouwbaar beeld geeft van de kennis van de leerling. In het talenonderwijs kan er daarom het best gebruik gemaakt worden van de pvt-test.
Anderson R.C, Freebody, P. 1983 Reading comprehension and the assessment and acquisition of word knowledge. Advances in Reading Language Research 2, 231-56.
Beeckmans R, Eyckmans J, Janssens V, Dufranne M, Van de Velde H. 2001 Examining the Yes/No vocabulary test: some methodological issues in theory and practice. Language Testing 18 (3), 235-274.
Eyckmans J, Beeckmans R, Van de Velde H. 2002 The Paired Vocabulary Test: an Alternative to Yes/No Vocabulary Tests? Second Language Vocabulary Acquisition Colloquium, 15-17.
Boogaards P. 2000 Testing L2 Vocabulary Knowledge at a High Level: the Case of the Euralex French Tests, Applied Linguistics 21/4, 490-516.
Cronbach L.J. 1942 An analysis of techniques for diagnostic vocabulary testing. Journal of Educational Research 36, 206-17.
Chapelle C.A. 1994 C-tests valid measures for L2 vocabulary research? Second Language Research 36, 206-17.
Eyckmans J. 2001 De vertekening van het antwoordgedrag in de ja/nee woordenschattoets. Toegepaste taalwetenschap in artikelen 2, 79-90.
Hazenberg, S. 1994 Een keur van woorden.
Huibregtse I, Admiraal W, Meara P. 2001 Scores on a yes/no vocabulary test: correction for guessing and response style. Language testing 18, 227-245.
Joe A, Nation P, Newton J. 1988 Vocabulary test difficulty and item types. Unpublished paper.
Juilland A.G. 1970 Frequency dictionary of French words. Mouton.
Laufer B, Nation P. 1995 Vocabulary size and use: Lexical richness in L2 written production. Applied Linguistics 16, 307-22.
Laufer B, Nation P. 1999 A Vocabulary-size test of controlled productive ability. Language Testing 16, 33-51.
Meara P, Buxton B. 1987 An alternative to multiple choice vocabulary tests. Language Testing 4, 142-151.
Meara P, and Jones G. 1988 Vocabulary size as a placement indicator. Applied Linguistics in Society, British Studies in Applied Linguistics 3. London: Centre for Information in Language Teaching and Research.
Meara P, Jones G. 1990 Eurocentres Vocabulary Size Test. 10KA. Zürich: Eurocentres Learning Service.
Meara P. 1992a Euralex French Tests. Swansea: Centre for Applied Language Studies.
Meara P. 1992b EFL vocabulary tests. Swansea: Centre for Applied Language Studies.
Meara P. 1992c New approaches to testing vocabulary knowledge. Swansea: Centre for Applied Language Studies.
Mobärg M. 1997 Acquiring, teaching and testing vocabulary. International Journal of Applied Linguistics 7/2, 201-219.
Nation P. 1983 Testing and teaching vocabulary. Guidelines 5, 12-25.
Nation P. 1990 Teaching and Learning Vocabulary. New York: Newbury House.
Neven A. 2002 Ontwikkeling van een dieptetoets woordenschatkennis op basis van substantief + werkwoord. Toegepaste taalwetenschap in artikelen 68, 77-92.
Nunnally J.C, Bernstein I.H. 1994 Psychometric theory. 3rd edn. New York: McGraw-Hill.
Read J. 1993 The development of a new measure of L2 vocabulary knowledge. Language Testing 10, 355-71.
Richards J. 1976 The role of vocabulary teaching TESOL Quarterly 10, 77-89.
Singleton D, Little D. 1991 The second language lexicon: some evidence from university-level learners of French and German. Second Language Research 7, 62-81.
Wesche M, Paribakht T.S. 1996 Assessing second language vocabulary knowledge: depth versus breadth. The Canadian Modern Language Review 53, 13-40.
Zechmeister E.B, D’Anna C, Hall J.W, Paus C.H, Smith J.A. 1993 Metacognitive and other knowledge about the mental lexicon: do we know how many words me know? Applied Linguistics 14/2, 188-206.
Websites:
- http://culture2.coe.int/portfolio
- http://granddictionnaire.com
De bijlagen zijn enkel in pdf te bekijken (330 kb)
| home | lijst scripties | inhoud | vorige | volgende |